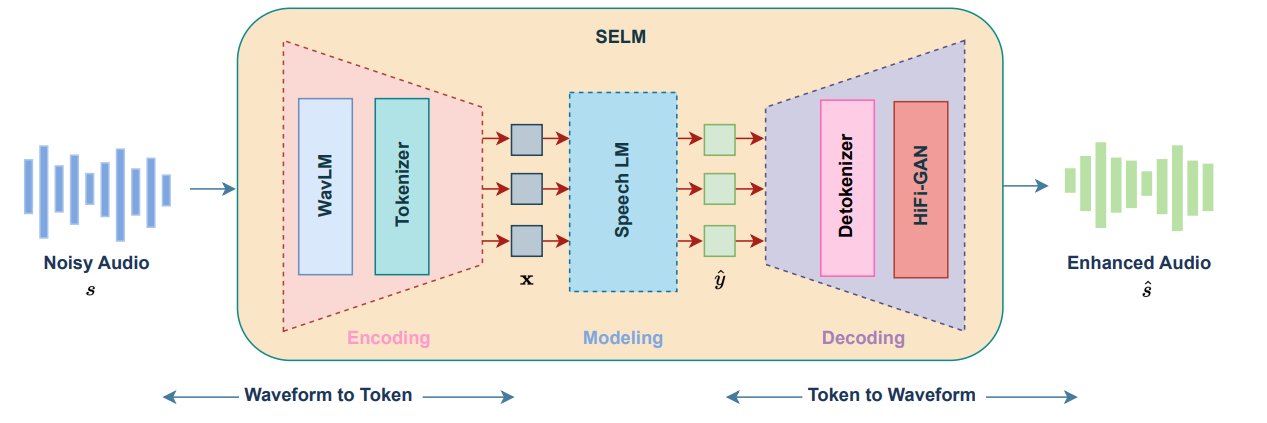
Overview of the SELM framework. SELM handles SE tasks by using transformer-based LMs conditioned on discrete tokens.
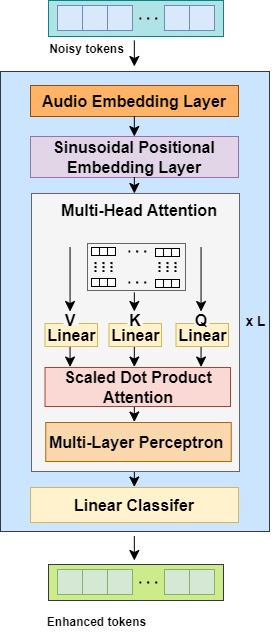
Language Models (LMs) have shown superior performances in various speech generation tasks recently, demonstrating their powerful ability for semantic context modeling. Given the intrinsic similarity between speech generation and speech enhancement, harnessing semantic information holds potential advantages for speech enhancement tasks. In light of this, we propose SELM, a novel paradigm for speech enhancement, which integrates discrete tokens and leverages language models. SELM comprises three stages: encoding, modeling, and decoding. We transform continuous waveform signals into discrete tokens using pre-trained self-supervised learning (SSL) models and a k-means tokenizer. Language models then capture comprehensive contextual information within these tokens. Finally, a detokenizer and HiFi-GAN restore them into enhanced speech. Experimental results demonstrate that SELM achieves comparable performance in objective metrics alongside superior results in subjective perception.
clean_1.wav
mix_1.wav
enhanced_1.wav
clean_2.wav
mix_2.wav
enhanced_2.wav
clean_3.wav
mix_3.wav
enhanced_3.wav
clean_4.wav
mix_4.wav
enhanced_4.wav
clean_5.wav
mix_5.wav
enhanced_5.wav
clean_6.wav
mix_6.wav
enhanced_6.wav
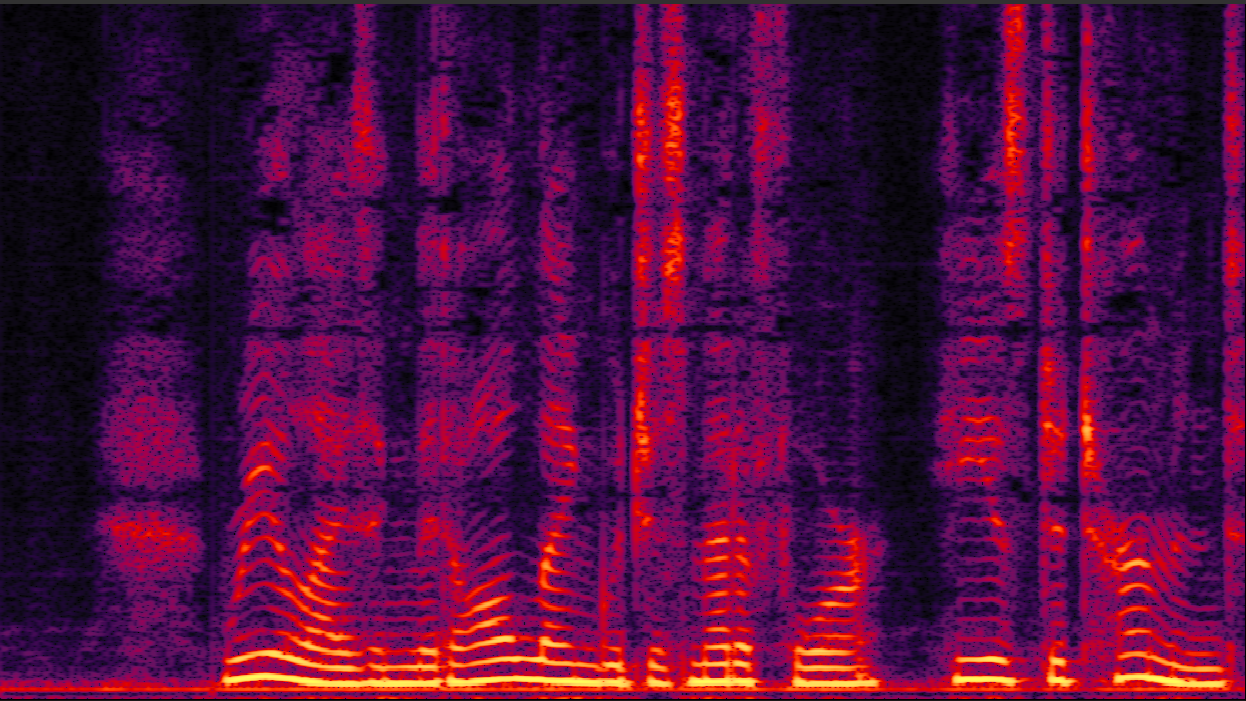
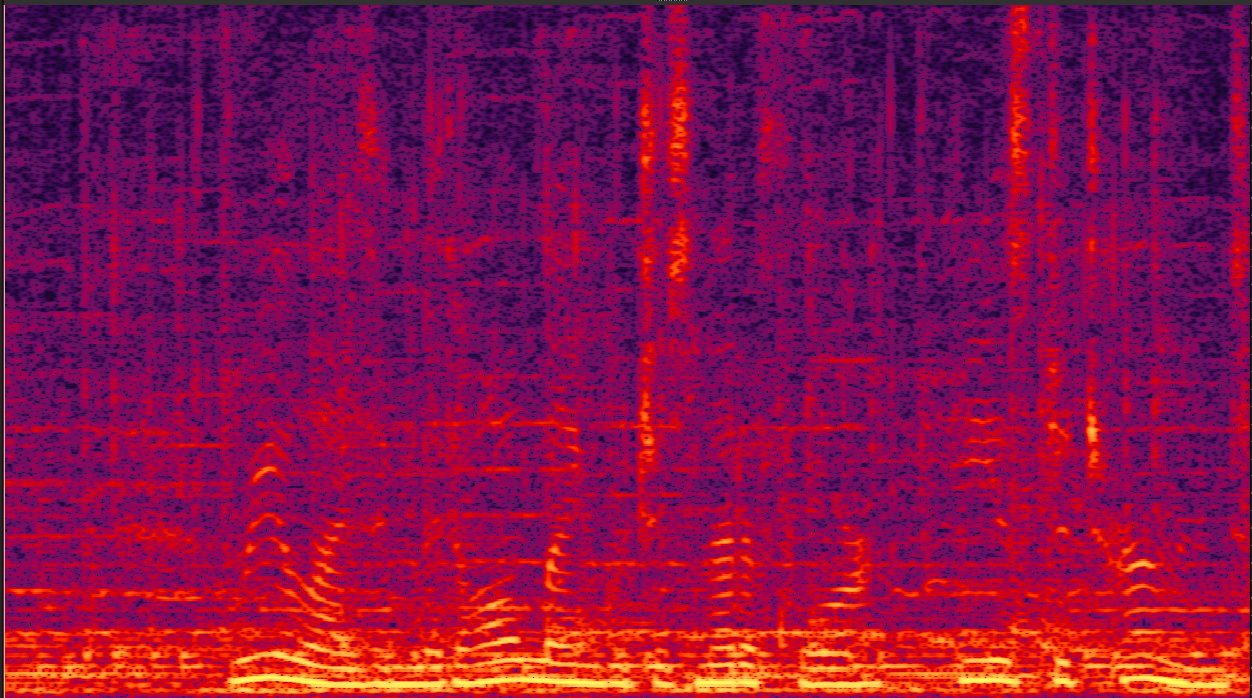
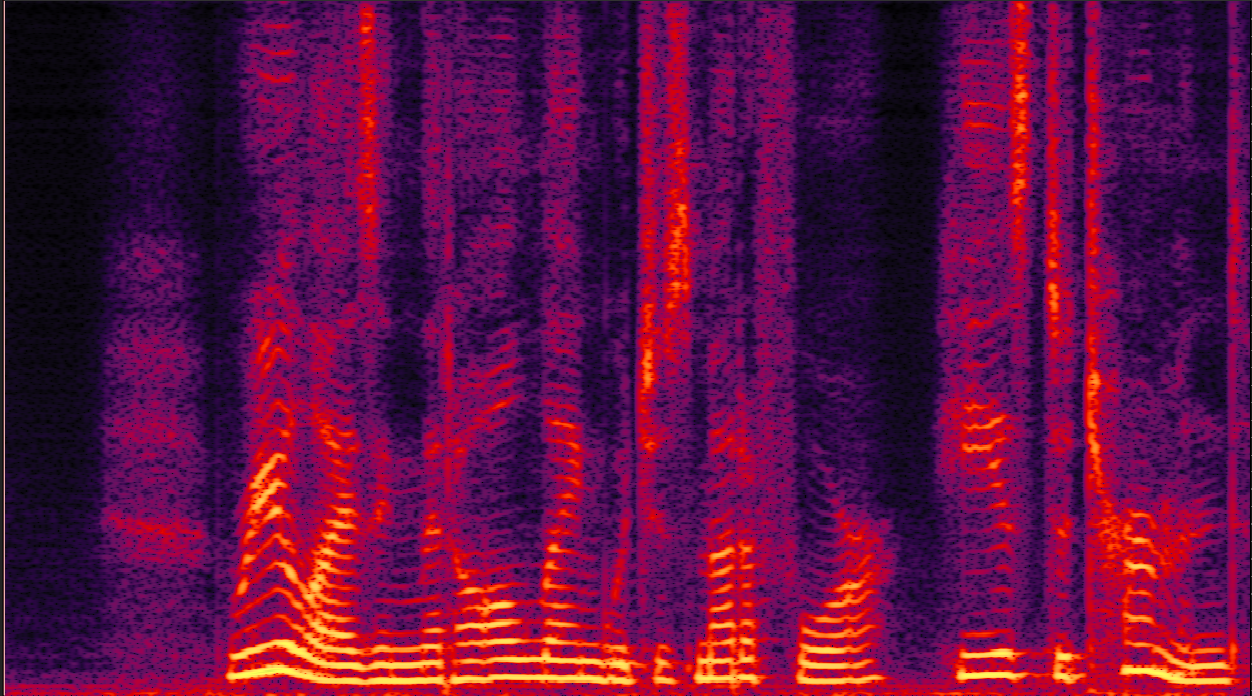
clean_7.wav
mix_7.wav
enhanced_7.wav